

As you might already know, VPC or Virtual Port Channel- is a multi-chassis enabling feature by Cisco, available on Nexus platforms. This protocol was needed to overcome the drawbacks of the spanning tree and make all resources useable.
I am not going to explain VPC or even show how it is configured. Long story short, two switches of the same model can be combined into a VPC domain, which can establish a single port channel, and the “peer link” is the main component that allows traffic traverse between the two switches as if they are a single switch.
People who really close to me know that since a long time ago I adopted the theory “Layer 2 is just padding”, which might make you laugh but I have my reasons and I might explain that later in a separate post or podcast.
VPC was never in my interest until today when I had a challenging scenario, that took me diving in VPC to understand how it is working and what to do or not to do when designing your network.
This story started when DC and SO engineers had a mission to migrate a specific service of many servers and VMs from a Datacenter “X” to another “Y”, but one requirement to have them migrated on steps “2 servers per activity” which requires keeping the L3 GW on old PEs in X location and extend Layer 2 using “R-VPLS” to the new location Y.
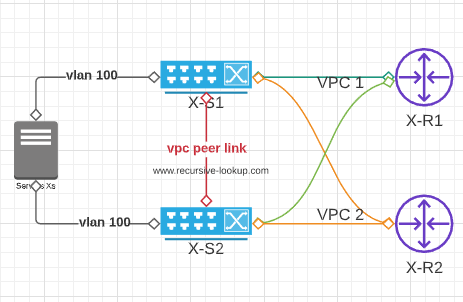 Figure 1
Figure 1
In Figure 1, you can see that servers are connected to 2 switches running VPC in domain 100, and 2 port channels towards the 2 PEs where we have the L3 GW in a VRF/VPRN, maintaining main & backup using VRRP.
So, from the core network perspective, not taking anything else into consideration, we decided to extend layer 2 from site X to site Y using VPLS and keep the L3 GW doesn’t matter in which location, this is formally known as Routed VPLS.
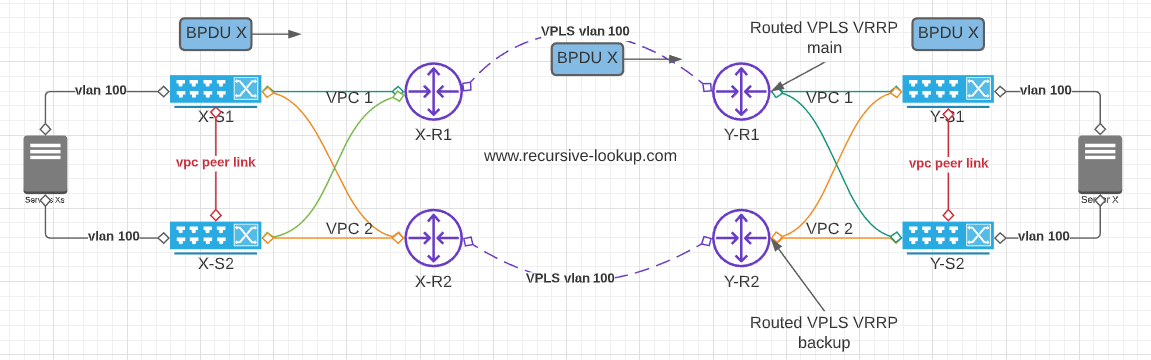
Figure 2
In Figure 2, it shows what was on the table, but looking forward, finding that a closed-loop will be detected as VPC pairs will receive BPDU over vpc1 and send it over vpc2 and vice versa. taking into consideration that by default, only the primary switch will send BPDU’s to VPC member ports. In fact, the secondary won’t process BPDU’s at all. If it receives a BPDU, it will be forwarded across the peer-link for the primary switch to process.
To avoid this closed-loop scenario, we finally decided to have R-VPLS “main to main” and on the backup routers, we keep the L3 configuration as is.
After configuration was placed and activating the new server in location Y, we found that the spanning tree blocked the port-channels facing the VPLS instance, although there is no closed-loop and as we already know VPC primary switch is processing the BPDU’s locally and not sending them back on the same VPC member ports or even to the secondary VPC.
During the troubleshooting session, we found that the two VPC pairs in both locations are using the same “system mac-address” so when VPC pair X generates BPDU with source mac address M, VPC pair Y will think it belongs to them as it has the same mac address, so loop detected and port blocked.
Simply, this happened as the same VPC domain ID was configured in both sites and this how switches generate their system mac address, we had two options to fix this:
1- remove the VPC configuration and define a new domain with different ID in the new location.
2- Define the mac address manually.
As you might already assume, yes we chose the second option which is less configuration and less impacting – 5 to 10 minutes VPC downtime. and fortunately, it was a new location with zero provisioned services yet.
This will let us think more about the scalability of our networks during the design phase and how smooth it is to accept unusual scenarios. In very critical networks a mistake like this in a LIVE service switches in front of a running datacenter will cost a lot, as it brings downtime, project delays, and more.
I hope this was informative for everyone 🙂